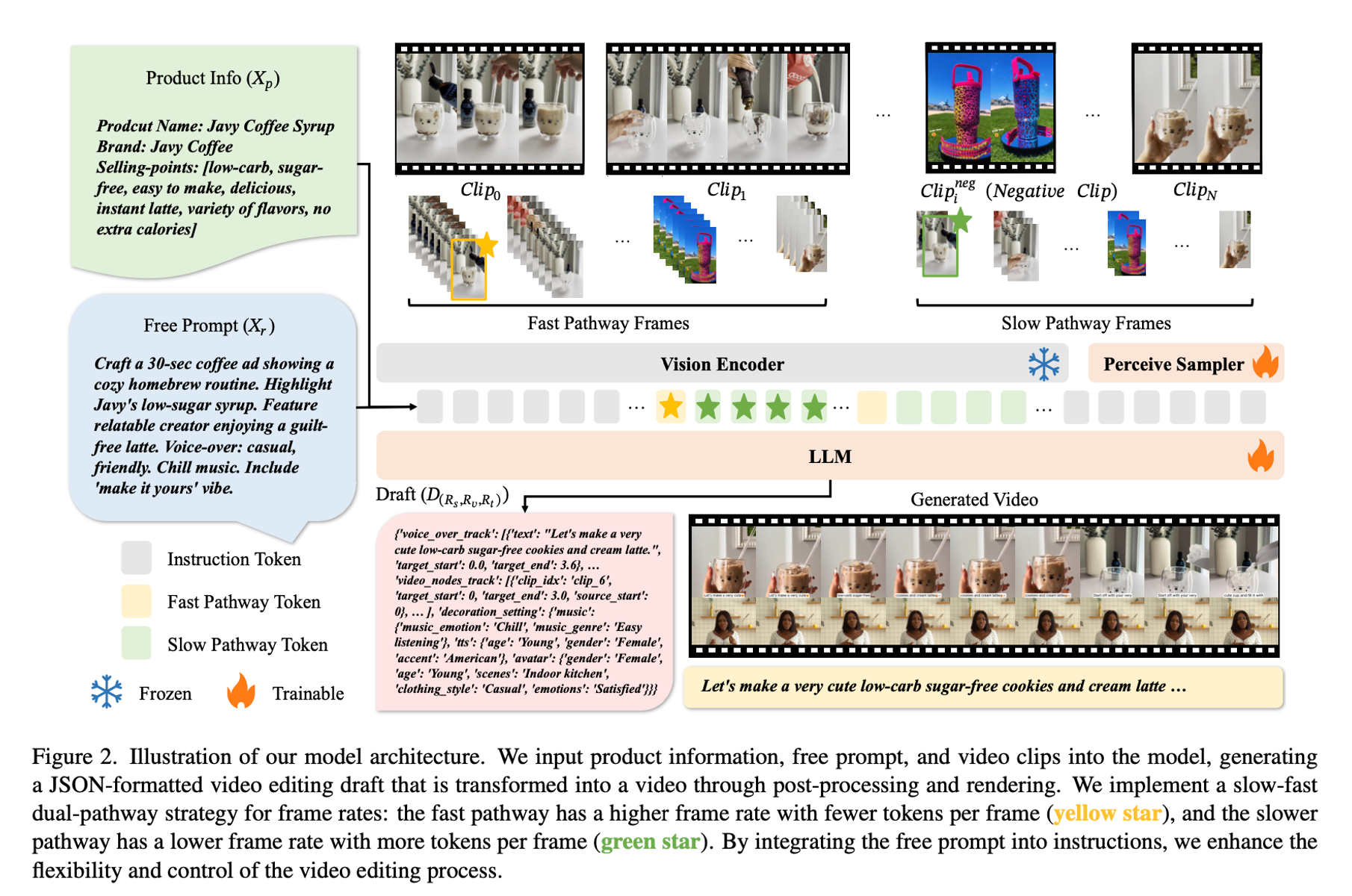

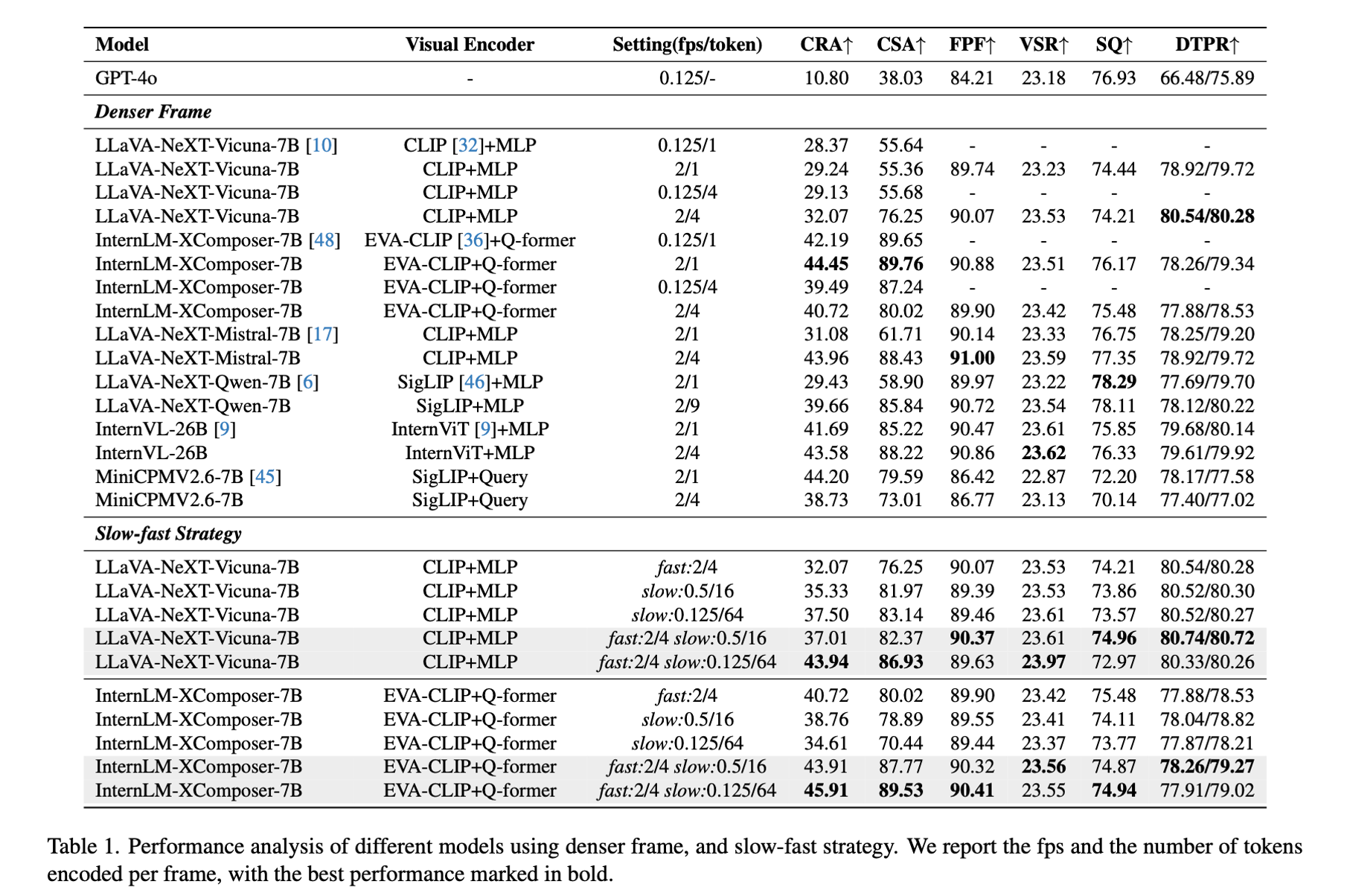
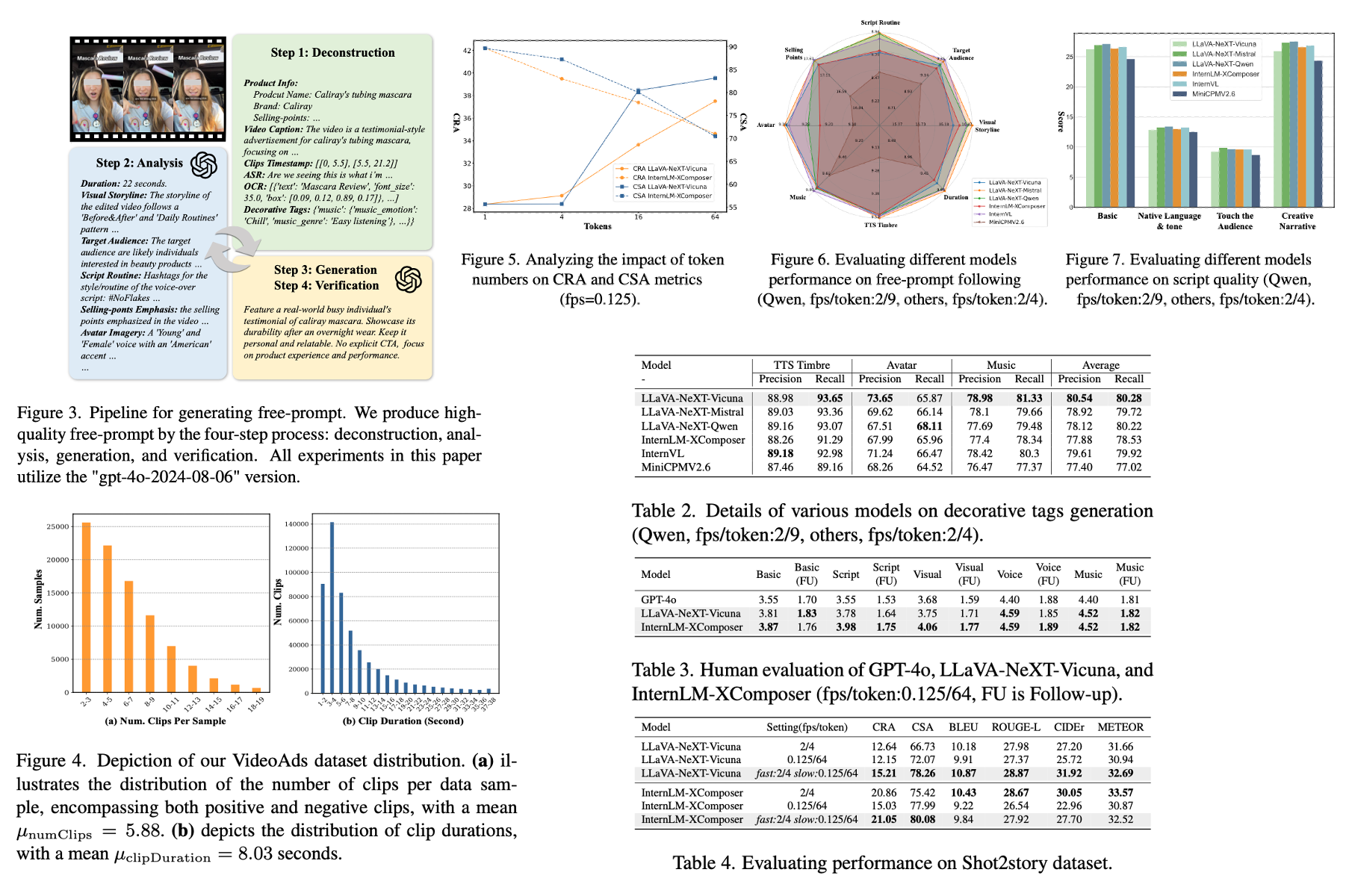
The exponential growth of short-video content has ignited a surge in the necessity for efficient, automated solutions to video editing, with challenges arising from the need to understand videos and tailor the editing according to user requirements. Addressing this need, we propose an innovative end-to-end foundational framework, ultimately actualizing precise control over the final video content editing. Leveraging the flexibility and generalizability of Multimodal Large Language Models (MLLMs), we defined clear input-output mappings for efficient video creation. To bolster the model's capability in processing and comprehending video content, we introduce a strategic combination of a denser frame rate and a slow-fast processing technique, significantly enhancing the extraction and understanding of both temporal and spatial video information. Furthermore, we introduce a text-to-edit mechanism that allows users to achieve desired video outcomes through textual input, thereby enhancing the quality and controllability of the edited videos. Through comprehensive experimentation, our method has not only showcased significant effectiveness within advertising datasets, but also yields universally applicable conclusions on public datasets.
• We propose a novel video editing framework with a multimodal LLM that clearly defines input-output
formats, streamlining production by managing material comprehension and arrangement in one step. To the
best of our knowledge, this is the first end-to-end MLLM-based video editing framework.
• We introduce an effective approach employing a denser frame rate and a slow-fast processing
strategy, which significantly enhances the model's ability to extract and understand temporal and spatial
video information.
• To improve the controllability of the model's output, we develop a text-driven video editing method
that ensures the final output aligns precisely with user expectations.
• We conduct comprehensive experiments and exploratory analyses, demonstrating that our proposed
video editing framework can optimally perform advertising short-video editing tasks. Moreover, our
framework generalizes well to public datasets, achieving applicable results.
@misc{cheng2025texttoeditcontrollableendtoendvideo,
title={Text-to-Edit: Controllable End-to-End Video Ad Creation via Multimodal LLMs},
author={Dabing Cheng and Haosen Zhan and Xingchen Zhao and Guisheng Liu and Zemin Li and Jinghui Xie and Zhao Song and Weiguo Feng and Bingyue Peng},
year={2025},
eprint={2501.05884},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.05884},
}